


Promoting collaborative business intelligence with Open Datastack
Our new business intelligence platform, Open Datastack, utilizes the innovative power of modern open-source technologies and creates a collaborative environment with interactive dashboards, data pipelines and workflows to efficiently extract, process and visualize data. The platform reduces the Time to Insight needed to implement data-based measures and decisions.
The complexity and fragmentation of modern data landscapes pose problems for many organizations. Data is often organized decentrally, is laborious to process, and requires complex processes that are diffi cult to scale. Static dashboards offer little room for interactivity or collaboration, and the lack of documentation of measures and decisions means that data is processed further in other tools. This results in a loss of context and a lack of comprehensibility.
Collaborative workflows instead of static reporting
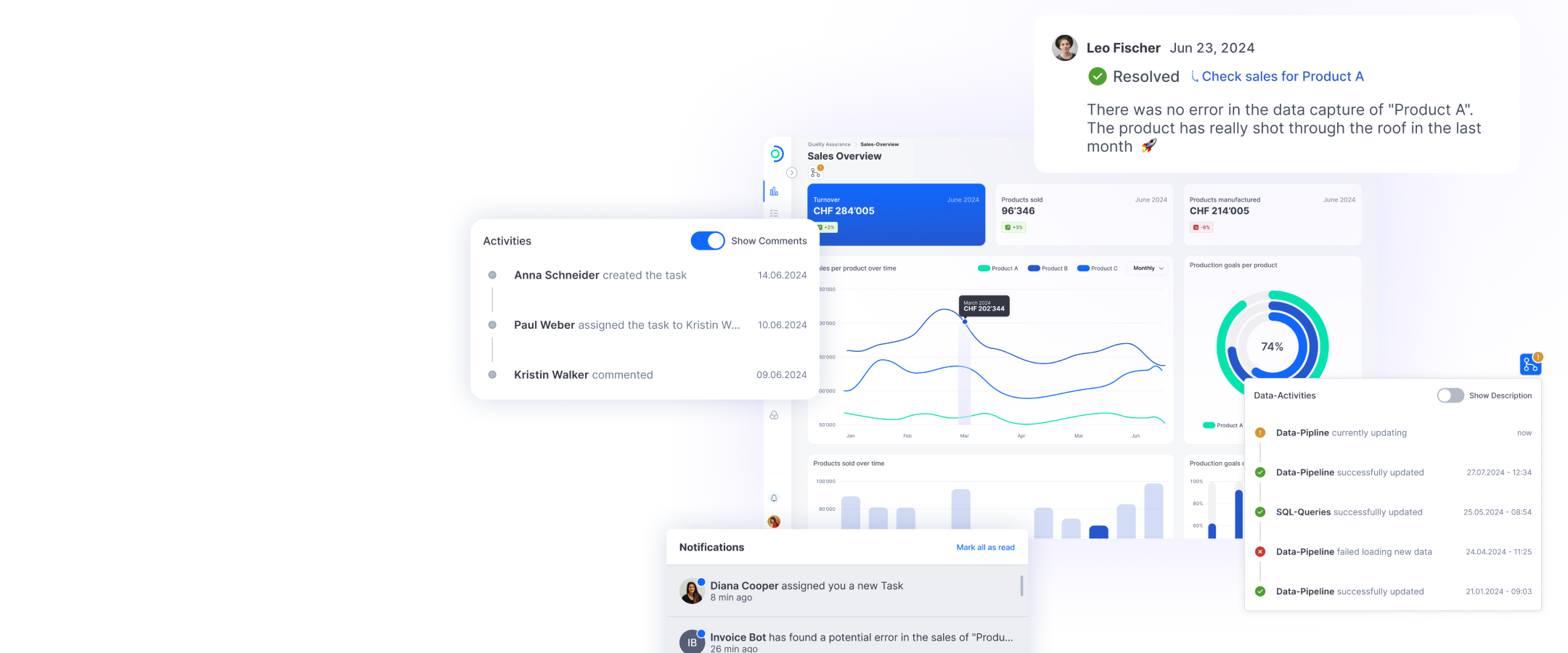
This is exactly where Open Datastack comes in. Interactive dashboards not only visualize data, but also map processes and promote collaborative working methods. Comments and tasks can be created directly on the dashboards and linked to specific data, while alerts, notifications and banners inform users about new features or any tasks or problems – for example, about newly assigned tasks or problems with data processing or data quality. These dynamic, collaborative and transparent workflows enable the users to plan and implement data- based projects directly on the platform without leaving the data environment and having to process data in other tools. The user-friendly interface with custom charts and flexible design system creates a clear understanding of the data and offers optimal user guidance for employees from different areas. From data extraction, storage and processing through to visualization: As a central business intelligence platform, Open Datastack offers all the building blocks that companies need to organize their data and use it profitably.
Sustainable and future-proof
Our platform is based on modern opensource components, conveys best practices in data engineering and can be flexibly integrated and individually expanded and adapted, thanks to open interfaces. Open Datastack is platform agnostic and reduces the risk of vendor lockins, as all customer-created resources such as dashboards, charts or data pipelines are implemented within open-source services and thus remain fully usable, even if Open Datastack upgrades are not installed in the future. The container-based platform can be operated in the cloud or onpremises with Kubernetes or locally on Docker, which simplifes end-to-end testing and individual further development. Open Datastack enables native lake house architecture and thus fulfills the requirements of a scalable infrastructure for growing data demands. With Open Datastack, companies bundle their data processes in a central platform that can be flexibly adapted to internal processes and user requirements. Its intuitive usability, collaborative functions and future-proof architecture make Open Datastack an indispensable solution for data-driven organizations. From management to data engineers to end users: Open Datastack offers clear advantages for every role and is the key to effective and sustainable use of data.
ti&m Special «digital banking»
Beyond banking: trends, tech and transformation
Open Datastack
The solution for collaborative BI
Open Datastack is a modular data platform that is based on open source components and is used both in the cloud and on-premises. The focus of Open Datastack is on interactive collaboration around data, dashboards and workflows.
Special, Digital-Trust
How Cyber Command benefits from the militia system
Gregor Hofer - Jun 25, 2024
Special, AI
Using your smartphone as a pen
Swisscom Sign // Since last fall, people through-out Switzerland have been able to sign contracts electronically using the My Swisscom app. The function is available to everyone, regardless of whether they are a Swisscom customer or not.
Andreas Tölke - Jan 10, 2024
Special, Future of Work
Working in the cloud – the challenges for data protection
Data protection // Sooner or later, every organization or business needs to address the question of digital transformation and therefore get to grips with the cloud. A number of aspects must be carefully considered first in order to avoid any legal pitfalls.
Ursula Sury - Oct 24, 2022